Oh, and the obligatory picture of cute animals

As I was going through Pip Black’s blog, I saw the diagonals again, and I might as well post whatever I worked on.
My pictures will not be quite as hazy though (apologies not accepted, Pip).
Recall the problem: You have a rectangular grid made up of m rows and n columns, where m and n are positive whole numbers (no imaginary grids, thank you). Draw a line from the upper left to the lower right corner—how many of the grid squares will the line pass through the interior of it? Question: whur the formula at.
As a provided example, if m = 4 and n = 6, we know that the diagonal passes through 8 squares.

If m = n, our square will pass through m (or n) squares. Special case.

Another one: if m = n + 1, the diagonal passes through 2m squares.
Another one: if m and n are both even, then we can look at the first (top left) quadrant and double the result.

The very average case: if m is even and n is odd, or vice versa, the pattern is pretty meh. Same goes for the two odd values.

EXCEPTIONS: As pointed out in the aforementioned blog, if m and n have a common divisor, a pattern evolves! One of the examples is mentioned above: if both are even, then they can be divided by into 4 rectangles. Similarly, if the greatest common divisor is 3, it can be broken down into 9 squares (i.e. 3 to the power of itself). We can make the conclusion that the we need only analyse the first top left rectangle in those situations, and then multiply the result (the number of squares passed) by the common divisor itself.

Intermission: I’m so thankful for technology.
Starting with a simple case, suppose our rectangle has values m and n such that the diagonal won’t through any of the grid points of the rectangle. Then, we know that the very first square will always be crossed by the diagonal, regardless of the values of m and n. We also know that the remaining rectangle has m – 1 rows, and n – 1 columns. For an average case, then, there will be (m – 1) + (n – 1) = m + n – 2 internal lines crossed, plus the one of the first top left square, so in total, m + n – 1.
Now for the generalisation of that. Since any two numbers have a greatest common divisor (at worst, it’s 1), then we know that gcd(m, n) – 1 grid points lie on the diagonal for any given values of m and n. We should therefore adjust the formula to accommodate this: m + n – 1 – (gcd(m, n) – 1) = m + n – gcd(m, n) squares will be crossed by a diagonal of a rectangle with a given number of rows m and a given number of columns n.
The conclusion Pip drew: d = m + n – gcd(m, n).
Good.
For some reason, I find proofs a lot simpler (structurally) in computer science (well, in CSC165) than I find those in math courses. I guess it contributes to the fact that I prefer the former to the latter; I find the hard, unapologetic structure of a proof in this course so much more preferable to the confusing flowing proof in courses like MAT157 or MAT240.
For example, here is one of my answers for a MAT240 assignment last term:

There is a clear logical structure to the proof, I contend, but I have no idea what it means anymore (I’m sure there was a time when I did). However, take any proof we have ever done in this class, and I will probably be able to understand it at any given point in the future, provided maybe a brief refresher on what some of the symbols mean.
It is true that mathematics deals with very different topics, but I think that there is an element of required knowledge involved in both, and it bothers me that I find CSC proofs so natural, and MAT proofs so foreign. I therefore tried to apply the same approach, hashtags and all, to my math classes over the past few weeks.
I then arrived at the somewhat-pathetic conclusion that structuring my proofs line-by-line, and indenting at just the right places, helps immensely with structuring my thought process.
A couple of years ago, I took a course about Empiricist philosophy. I didn’t expect to care for empiricism too much, and I didn’t, though the reason I took the course was the professor’s glowing reviews. What stood out was his opening remarks: “You may not remember much about what Locke and Berkeley thought; you may agree or disagree with them now, but in a few years you’re not likely to care. The one thing I, therefore, want you to take out of this course is how to think like them: how to think philosophically, and how to always battle with yourself in debate, so you can feel the satisfaction of truly proving something to yourself.”
I feel like I may forget everything I’ve learned in this course, but I think the way of structuring a logical proof (and by extension, arguments and essays) will stay with me for a while. It’s a little sad that it took all this time to figure it out.
While playing around with NetLogo software for another class, I found that there are sample models created for computer science topics, including one for the Dining Philosophers.
Essentially, the problem begins with any number of boring philosophers—boring because they only eat spaghetti or think (and therefore, they do not communicate). At any given time, a philosopher can be thinking, eating, or hungry and waiting to eat. There are as many forks as there are philosophers, but one requires two forks to actually eat.

In a way, the problem is similar to the halting problems we’ve discussed in class in the past couple of weeks, because it is an issue of ensuring that all philosophers get to eat without at ending up with ‘deadlock’, where each philosopher holds on to one fork stubbornly waiting for the second one.

The five philosophers halt their eating fairly quickly. Running the program with 20 philosophers last a lot longer, and I haven’t been able to make it halt (unless one were to set the probability of them being hungry very high, in which case they did eventually create a deadlock).

Also interesting that two philosophers didn’t seem to have an issue continuing eating: I’m thinking there is just a lower chance that both of them are not hungry and then become hungry at the exact same time, which I guess is the only way for them to each end up with one fork each.
My favourite solution to the problem is to introduce a waiter. Thus, if a philosopher were to become hungry, he would need to ask the waiter for food (i.e. permission to eat), and the waiter would act as the intermediary who ensures that everyone gets a turn at eating.
That way, if there are five philosophers (the number in the original phrasing of the problem, I believe), and there are two sitting beside each other who are currently not eating, they would normally grab the single fork available to them when they decide to eat, and thus create the gridlock. With the introduction of a waiter, however, one would simply have to wait until the fork actually becomes available. Another similar solution could introduce communication to the mix, where the philosophers somehow coordinate who gets to eat first.
So in the spirit of productive procrastination (re: when is that meeting during which all professors decide to have exams during the same three days?), I looked at optimising the max_sum function from class slash chapter 4.
The initial inefficient function is:
def max_sum(L):
1. maximum = 0
2. i = 0
3. while i < len(L):
4. j = i + 1
5. while j <= len(L):
6. total = 0
7. k = i
8. while k maximum:
12. maximum = total
13. j = j + 1
14. i = i + 1
15. return maximum
and the faster version provided is:
def faster_max_sum(L):
1. maximum = 0
2. i = 0
3. while i < len(L):
4. total = 0
5. j = i
6. while j maximum:
9. maximum = total
10. j = j + 1
11. i = i + 1
12. return maximum
max_sum 
faster_max_sum 
Here’s my attempt:
def fastest_max_sum(L):
1. maximum = 0
2. current = 0
3. for element in L:
4. current = max(current + element, 0)
5. maximum = max(maximum, current)
6. return maximum
Ergo, if we keep track of the maximum sum thus far, and, going through the elements in the list, replace the maximum sum when we find a better sum, we get the same result as the two functions above. By definition of having only one loop, the time to complete the task is faster, but I’ll attempt to prove it formally. I will use the accounting technique used in class, rather than the one used in tutorials (i.e. I will count lines rather than operators).



Not really sure if I’m correct in asserting that the for loop happens 3n times, though.
How does Perez Hilton do it?
Mostly for myself, of course.
Some of the other SLOGs stood out from the class, and I just wanted to let the writers know that I appreciated them and I hope to address some of their comments in the near future.
The Russel Paradox, Who Shaves the Barber: delightful, and motivates me to look at some of those problems to which Prof. Heap referred previously.
A Blog, (about school): informative, and has a collection of classroom quotes.
Sophia Huynh’s peph8 has drawings, so it’s an automatic yes.
Mohammad Abubakr’s Experiences: while my math courses forced me to learn 
We’ll see how it progresses. Hopefully more interesting problems will come up in some of these!
This warrants its own post.
After my brief affair with diagonalisation, I accidentally learnt what it is anyway.
For those interested in philosophy, I recommend taking PHL346 – Philosophy of Mathematics. In last week’s lecture, we took a detour to examine Cantor’s diagonal argument. We discussed that the set of natural numbers, 



Cantor proved, however, that the set of rational numbers 
The rough version of the proof that made sense to me is as follows:
Let 

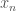
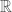

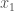

I know that we will probably be getting to diagonalisation soon in the course, and it’s quite interesting to see how the proofs we’ll be learning are becoming more sophisticated.
The first month of CSC240 covered material at a speed that is certainly illegal in many American states.
During the last lecture I attended, we (supposedly having already learnt how) had to prove some theorem by diagonalisation. My feelings of confusion turned into those of defeat when the girl next to me told me that she already got the answer, because she took 165 in the previous term. And they say it’s not a prerequisite!
It is nice to go to a lecture knowing that the material will be presented at a respectable speed, especially when introducing proofs. The worst feeling is doing something without knowing why you’re doing it. Oh, purity.







